
Workflow for a Notebook Project#
Teams must follow EDS book submission guidelines. They should open a Notebook Idea in the EDS book repository to describe and discuss initial ideas of the paper to reproduce. EDS book provides templates of notebook repositories in Python, R and Julia that aim to facilitate teams submission. Teams should reproduce the study’s results as closely as possible using the available data and code. They should document their process and any deviations from the original study in a Jupyter notebook.
The following workflow can be used during the reproducibility challenge:
Each team member (or as a group) should carefully read the paper and identify the data used/needed, software used and overall what you would have to reproduce during the challenge;
Choose the notebook template depending on the programming language (Python, R and/or Julia) and click on “use this template” button to create a new repository. This step should be done by the technical lead of your team only e.g. only one repository needs to be created.
The team lead (owner of the repository) adds all the other team members as collaborators to the repository.
Create issues to organize and dispatch the work. You may use GitHub project but make sure all the team members are acquainted with the procedures put in place in your team;
The Data Manager can create a bucket (read/write) to allow all the team members to share data and work collaboratively. Do not share access keys to anyone, including to any team members: access keys should remain private. Alternatively, anyone can create buckets but the Data Manager should make sure the storage is optimized and try to avoid duplication of data. All the bucket names should start with
repro-team-XX-*whereXXis your team member (01,02, etc.) as shown on the figure below: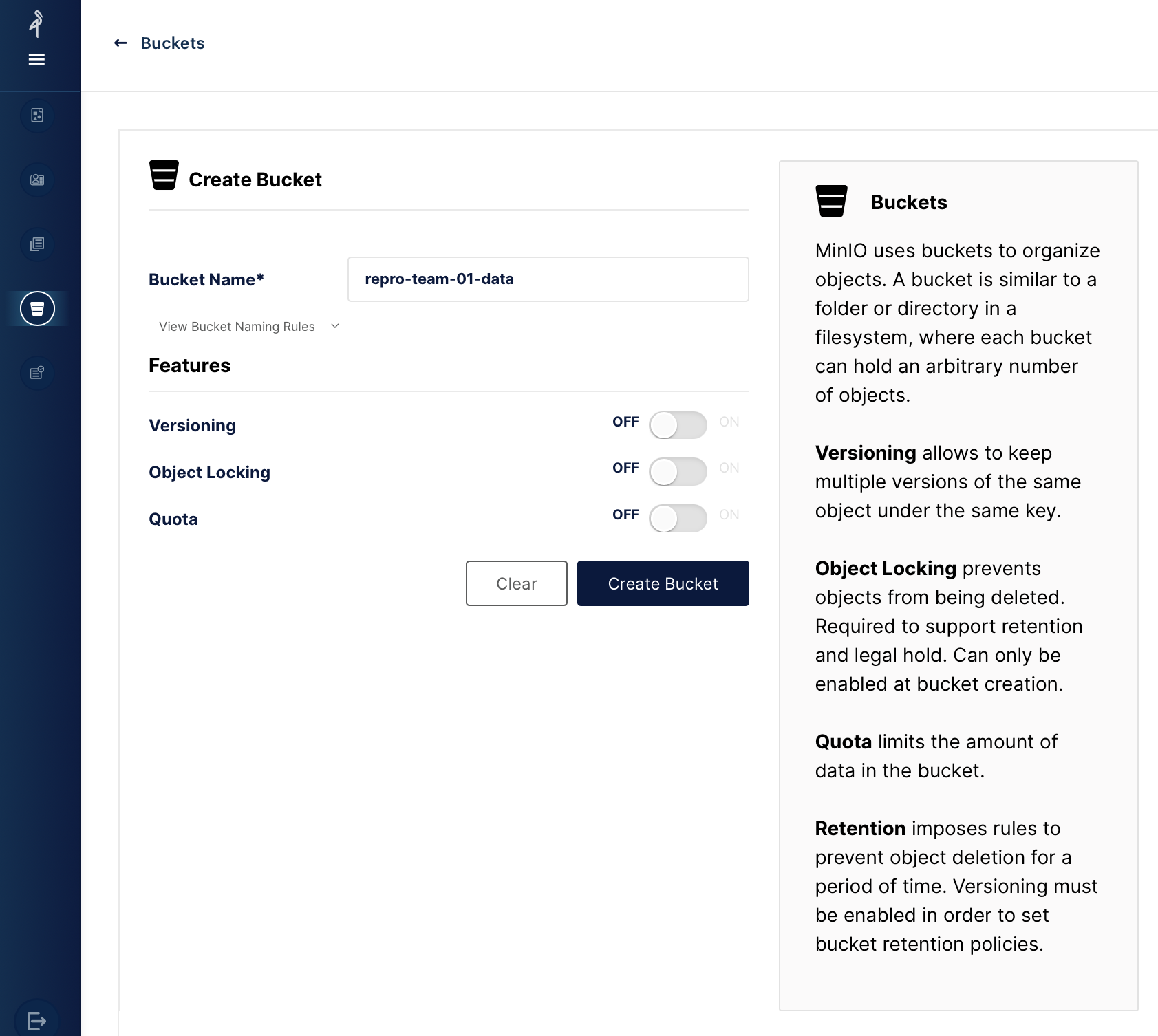 All team member of a given team can read/write data in a private bucket created by a team member. However, each team member will have to create his/her/they own access keys to read/write data in the team bucket.
All team member of a given team can read/write data in a private bucket created by a team member. However, each team member will have to create his/her/they own access keys to read/write data in the team bucket.If you want access using the Python package you need to first create
access keysas shown below:
Start working (incrementally!) on reproducing the paper. Testing independent sections is recommended. Don’t forget to take regular breaks and HAVE FUN! Whenever you have achieved a milestone (can be data downloaded, a plot, etc.), make sure to communicate with your peers so that the team presenter can gather the necessary information to show your progress/pending issues during checkpoints.
At the end of the reproducibility challenge, the Data Manager will have to archive the data used to reproduce the paper.
Note
To save resources and reduce the energy footprint of the reproducibility challenge, we kindly ask you to shutdown and close your JupyterHub at the end of each day. First select “Hub Control Panel” in the File Tab:
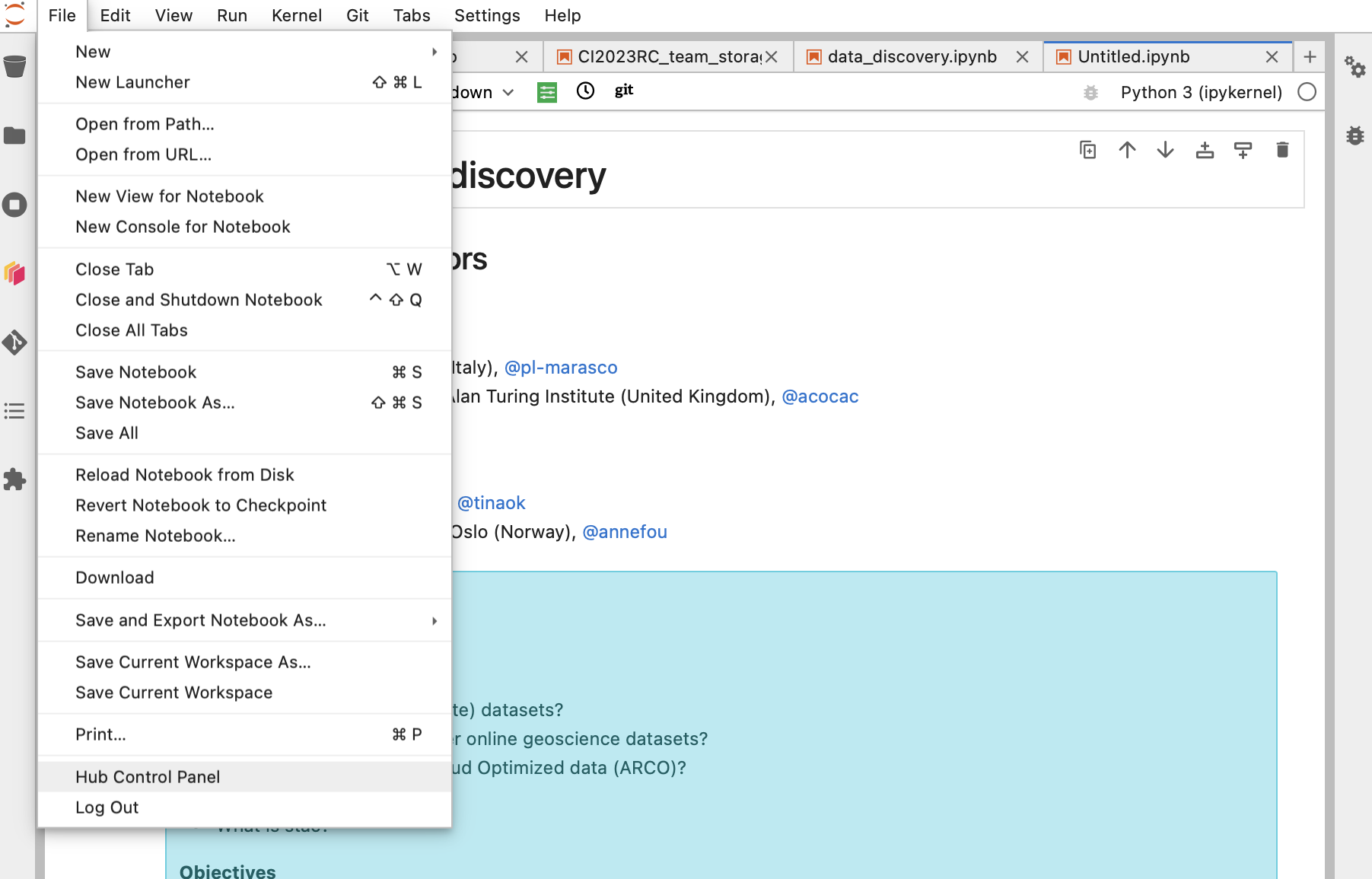
and then click on “Stop My Server” as shown on the figure below:
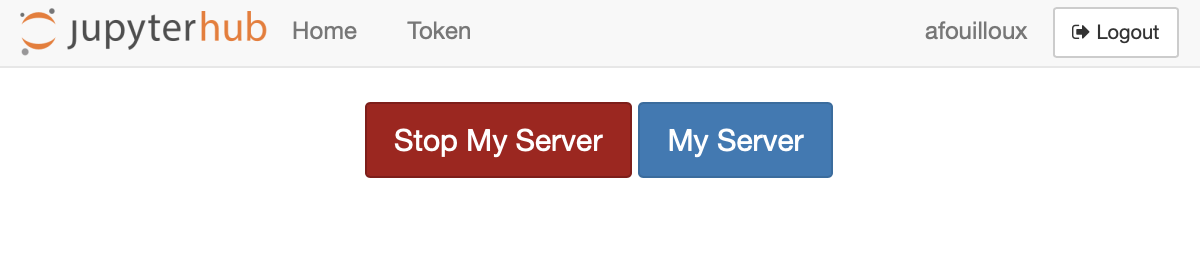
When your server is not running (stopped), the red button (see figure above) disappears and only the blue button “My Server” remains. To start your sever again, you can click on it and you will be redirected to JupyterLab.
At all stages, do not hesitate to ask for help in the Climate Informatics 2023 slack channel!